
Embeddings for LLMs and cosine similarity explained
A not too technical overview of how to map arbitrary length texts to fixed length vectors and translate semantic similarity into distances in a vector space.


Introduction
Embeddings are crucial for large language models (LLMs) because they provide a dense, low-dimensional representation of words, phrases, or other input features, capturing the semantic similarities and syntactic properties within the high-dimensional space of natural language. By transforming discrete linguistic elements into continuous vectors, embeddings enable LLMs to process and understand the nuanced relationships and contexts of language elements.
This foundational representation facilitates the model's ability to perform a wide range of tasks, from understanding sentiment and thematic content to generating coherent and contextually relevant text. Additionally, embeddings allow LLMs to generalize from seen to unseen data, making them more effective in handling the variability and complexity inherent in human language, ultimately enhancing the model's performance in natural language understanding and generation tasks.
This article explores the concept of embeddings, tracing their evolution from simple one-hot encoding techniques to sophisticated models like GPT, and delves into their workings, applications, and the services that have made their advanced capabilities widely accessible. We also explain the problems with the usual measurement of distances in high-dimensional vector spaces and explains the measurement of similarity with cosine similarity.
Objective of Embedding Tokens in a Vector Space
The primary goal of embedding tokens—whether they are words, sentences, or any form of discrete data—into a vector space is to capture and represent their meanings, relationships, and properties in a form that computers can understand and process. This involves mapping each token to a point in a high-dimensional space where the geometric relationships between points reflect the semantic or contextual relationships between the tokens. By doing so, embeddings allow algorithms to perform sophisticated linguistic and semantic analysis, making sense of language in a way that mirrors human understanding.
History of Embedding
One-Hot Encoding
The journey of embeddings begins with one-hot encoding, a simple yet limited approach where each word in a vocabulary is represented as a vector of zeros except for a single one at the index corresponding to the word in the vocabulary list. While straightforward, one-hot encoding suffers from high dimensionality and fails to capture any semantic relationships between words.

Word2Vec
The introduction of Word2Vec by researchers at Google in 20131 marked a significant leap forward. Word2Vec models generate embeddings that capture a wealth of semantic and syntactic relationships by using the context in which words appear. The model uses two architectures—Continuous Bag of Words (CBOW) and Skip-Gram—to predict words based on their context or vice versa, effectively learning representations that cluster similar words together in the vector space.

Transformers
The development of the Transformer architecture, introduced in the seminal paper "Attention is All You Need" in 20172, revolutionized NLP by enabling models to handle sequences of data with unprecedented effectiveness. Unlike previous models that processed data sequentially, Transformers use self-attention mechanisms to weigh the importance of different words in a sentence, regardless of their distance from each other. This innovation laid the groundwork for models like BERT3, which further refined the ability of embeddings to capture contextual nuances.
GPT
Building on the Transformer architecture, OpenAI's GPT (Generative Pre-trained Transformer) series, culminating in ChatGPT, represents the cutting edge of embedding technology. ChatGPT utilizes deep learning to generate human-like text based on the input it receives, showcasing the incredible potential of embeddings to understand and produce language with a high degree of coherence and relevance.
How Does It Work?
At its core, the process of creating embeddings involves training a model on large datasets to adjust the vector representations of tokens in such a way that the distances between vectors correspond to semantic or syntactic similarities. Techniques like neural networks, particularly those based on the Transformer architecture, are used to iteratively adjust these vectors, minimizing the difference between the predicted and actual contexts in which words appear.
Similarity Aspects and Spatial Nearness
A key feature of embeddings is their ability to encode semantic similarity as spatial nearness within the vector space. This means that words with similar meanings are located closer to each other. This property is exploited in various applications, such as finding synonyms, translating languages, and even creating analogies, by leveraging the geometric relationships between vectors.
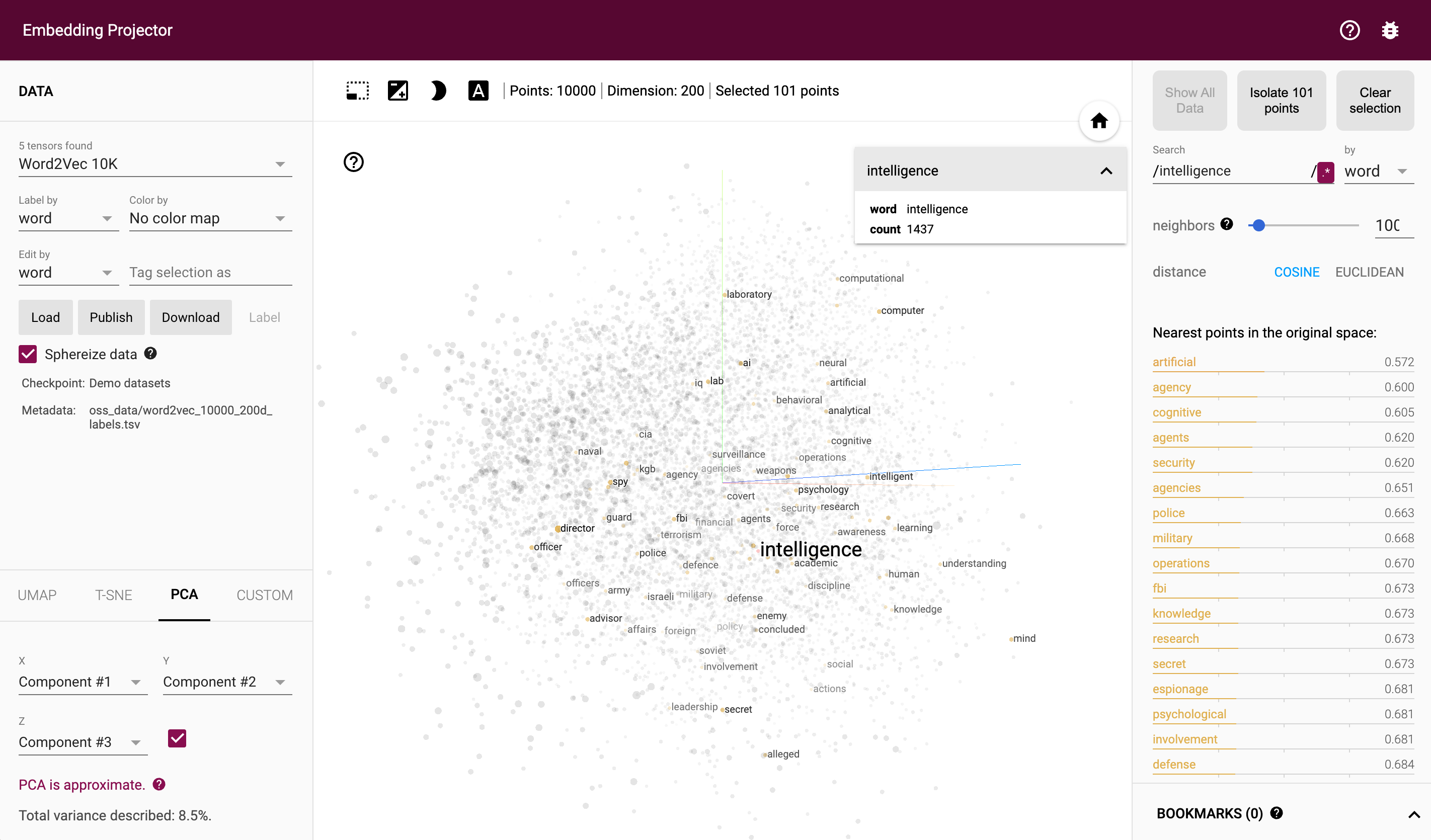
How to measure similarity
In mathematics, the concept of distance is far more flexible than the conventional notion often used in everyday reality, where distance is typically measured using the Euclidean metric. This flexibility allows for the adaptation of distance measurements to suit the nuanced needs of different mathematical and real-world scenarios, especially in the realm of high-dimensional vector spaces4.
Euclidean distance, while intuitive and straightforward in lower dimensions, becomes less effective in high-dimensional spaces. A more nuanced approach is needed here, especially due to phenomena that challenge our intuitive understanding of "distance", the curse of dimensionality5. One such phenomenon is the tendency for distances between points to become uniformly similar as dimensionality increases. In high-dimensional spaces, the Euclidean distance between any two points tends to a common value, making it increasingly difficult to distinguish between near and far points based on their Euclidean separation alone. This uniformity implies that in the context of Euclidean distance, all points appear to lie on the surface of a sphere relative to each other, emphasizing the orientation or directionality of vectors over their absolute positions or lengths.
The Euclidean distance between two vectors (points) p and q in an n-dimensional space is defined by the formula:
Cosine similarity addresses these challenges by measuring the angle between two vectors, effectively assessing their orientation or directional similarity. The cosine similarity between two vectors a and b is given by:
where
denotes the dot product6 of the vectors, and their magnitudes (norms).
This metric is particularly insightful in high-dimensional contexts for several reasons:
Orientation over Distance: Cosine similarity focuses on the angle between vectors, offering a measure of how vectors are oriented relative to one another. This is crucial in high-dimensional spaces where the Euclidean distance between points becomes uniformly similar. By comparing the cosine of the angles, cosine similarity highlights the relative orientation of vectors, i.e. the angle between the vectors, effectively distinguishing between them based on their directional relationships rather than their spatial separation.
Robustness to Length Uniformity: In high-dimensional spaces, not only do distances between points converge, but the notion of "closeness" also shifts towards a directional rather than a purely spatial interpretation. Cosine similarity leverages this by essentially measuring the orientation of vectors of similar length. This is akin to acknowledging that, due to the uniform distance phenomenon, each point in a high-dimensional space is at the center of its own universe, with all other points lying on the surface of a sphere surrounding it, as defined by Euclidean distance. Therefore, cosine similarity provides a meaningful way to assess similarity or relatedness in such environments by focusing on how vectors point in relation to each other rather than how far apart they are in traditional spatial terms.
In summary, cosine similarity offers a way to circumvent the limitations of Euclidean distance in high-dimensional spaces by focusing on the geometric properties that remain discriminative and informative, such as the angles between vectors. This makes it an essential tool in the analysis and machine learning tasks involving high-dimensional data.
A practical example
I used the OpenAI Embedding API7 to embed job titles in a 1,536-dimensional vector space to identify the best matching job title for a given job title. For more details, see my post titled “How to create a CustomGPT with actions“.
Conclusion
In conclusion, the evolution of embeddings from simple one-hot encoding to the sophisticated models of today exemplifies the rapid advancement in machine learning and NLP. By enabling machines to process and understand language in a contextually aware manner, embeddings have opened up new frontiers in human-computer interaction, data analysis, and beyond, with the potential for even greater achievements as the technology continues to evolve. Today, embeddings are at the heart of a wide array of applications, from enhancing conversational AI and content generation to powering complex sentiment analysis and language translation tasks, illustrating their critical role in bridging the gap between human linguistic complexity and computational processing.
Resources
https://platform.openai.com/docs/guides/embeddings
https://huggingface.co/blog/getting-started-with-embeddings
https://www.tensorflow.org/text/guide/word_embeddings
https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html
https://projector.tensorflow.org/
https://cookbook.openai.com/examples/get_embeddings_from_dataset
https://arxiv.org/abs/1310.4546
https://arxiv.org/abs/1706.03762
https://arxiv.org/abs/1810.04805v2
For the OpenAI API, by default, the length of the embedding vector will be 1536 for text-embedding-3-small or 3072 for text-embedding-3-large
The Elements of Statistical Learning contains a nice discussion of the curse of dimensionality (p. 22).
See here for more details about the dot product: https://en.wikipedia.org/wiki/Dot_product
https://platform.openai.com/docs/guides/embeddings