
How does RLHF work?
Understanding Reinforcement Learning from Human Feedback (RLHF) in detail without getting too technical.


Introduction
This article delves into the intricate world of Reinforcement Learning from Human Feedback (RLHF), distinguishing it from the commonly discussed Supervised Fine-Tuning (SFT) processes in the domain of machine learning. While SFT has its merits, RLHF emerges as a potent alternative for scenarios where the desired model output is complex and not readily attainable through supervised methods.
This article aims to shed light on the foundational principles of RLHF, illustrating its workings in a non-technical manner while drawing connections to general reinforcement learning (RL) principles. We explore the unique approaches adopted by leading entities in the field, including OpenAI, Meta AI, and Google, in implementing RLHF to enhance the performance and alignment of language models with human preferences.
RLHF is characterized as a training procedure tailored for fine-tuned language models, designed to further refine model behavior to better resonate with human preferences and instruction adherence. This method has been pivotal in advancing the development of large language models (LLMs) by significantly improving their usability and safety through meticulous alignment with human expectations. However, the implementation of RLHF is not without its challenges. It demands considerable computational power and a vast amount of annotated data, posing a formidable barrier to its widespread application.
Training a language model with reinforcement learning was, for a long time, something that people would have thought as impossible both for engineering and algorithmic reasons. What multiple organizations seem to have gotten to work is fine-tuning some or all of the parameters of a copy of the initial LM with a policy-gradient RL algorithm, Proximal Policy Optimization (PPO). (Source)
The accessibility of RLHF as a service to customers or users remains limited, with few exceptions1. This exclusivity underscores the sophisticated nature of RLHF and its positioning as a specialized tool within the machine learning landscape, rather than a broadly available service. Through this exploration, the article aims to provide readers with a comprehensive understanding of RLHF, its significance, and the challenges it addresses in the quest for creating more human-aligned AI systems.
Training for alignment
The diagram provided by OpenAI outlines a comprehensive three-stage process integral to the development of advanced language models. These stages are Supervised Fine-Tuning, Training of a Reward Model, and Reinforcement Learning. Each stage plays a crucial role in refining the model's performance, ensuring it aligns closely with human expectations and preferences.
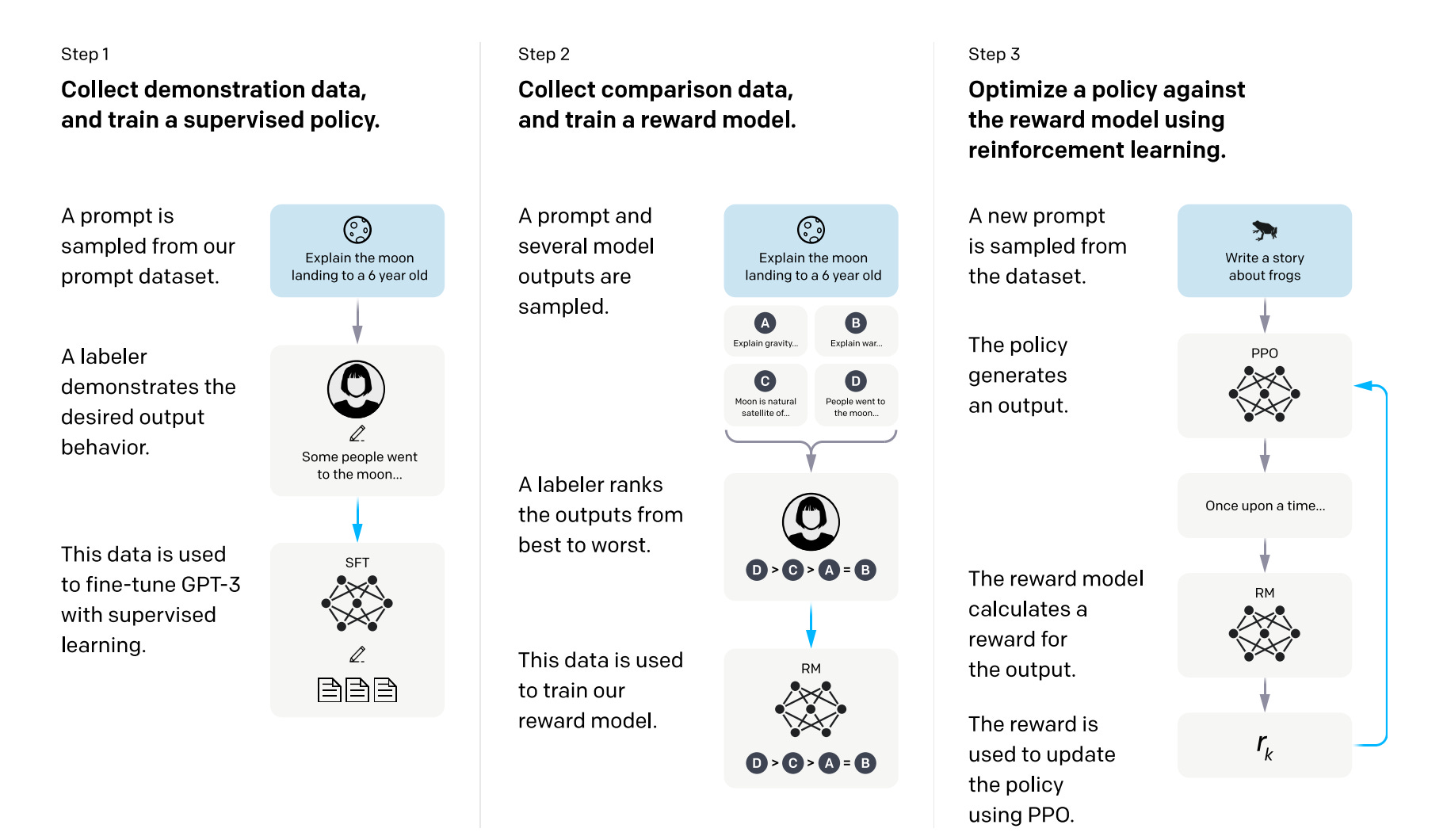
Below, we delve into each of these pivotal steps, offering a deeper understanding of their importance and how they collectively contribute to the creation of more sophisticated, responsive, and aligned AI systems.
Supervised Fine-Tuning: Adjusts a pre-trained model to specific tasks through supervised learning, enhancing its accuracy on similar tasks.
Training of a Reward Model: Develops a model to evaluate outputs based on human feedback, using comparisons to quantify alignment with human preferences.
Reinforcement Learning: Uses the reward model to guide the language model's outputs, refining its responses to better meet human standards.
Together, these steps form a robust framework for enhancing language model performance, each stage building upon the last to ensure the model not only understands and responds to human input but does so in a manner that is increasingly aligned with human expectations.
Step 1: Supervised Fine-Tuning (SFT)
Supervised Fine-Tuning (SFT) is a prevalent approach within the realm of machine learning, specifically in refining the capabilities of pre-trained models to better suit specific tasks or data domains2. This process, commonly available as a service to customers through platforms like OpenAI3 and Google4 for some models, involves adjusting a pre-existing model's weights through supervised learning. The primary objective of SFT is to enhance model performance on targeted tasks by training it on a curated dataset where both the inputs and the desired outputs are well-defined and labeled.
The following is an example of a simple prompt completion pair format5.
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}The procedure of SFT operates by exposing the pre-trained model to a task-specific dataset, allowing it to learn from examples that closely mirror the task it needs to perform. This learning phase involves minimizing a loss function, which quantifies the difference between the model's predictions and the actual desired outputs. Through iterative updates to the model's parameters, SFT aims to reduce this discrepancy, thereby improving the model's accuracy and effectiveness on the task at hand.
Despite its widespread application and the tangible benefits it offers, SFT comes with inherent limitations. One major constraint is its dependency on large volumes of high-quality, labeled data. Acquiring such datasets can be resource-intensive and may not always be feasible for all types of tasks or domains. Additionally, SFT can lead to overfitting, where the model becomes excessively tailored to the training data, compromising its ability to generalize to new, unseen data. Furthermore, SFT does not inherently address the complexity of outputs or the alignment of model behavior with nuanced human preferences, areas where alternative approaches like Reinforcement Learning from Human Feedback (RLHF) may offer superior outcomes.
Step 2: Training of a Reward Model
The core objective of RLHF is to train language models to generate outputs that align with human preferences and instructions. To achieve this, RLHF employs a reward model based on neural networks. This model is trained using data collected from human annotators, who compare pairs of model outputs and select the one that best meets the desired criteria.
This is an example of a human preference data set used to train the reward model6. It shows a person's preference for candidate 0: “Enjoy some fun in the sun at Gulf Shores.“
{"input_text": "Create a description for Plantation Palms.", "candidate_0": "Enjoy some fun in the sun at Gulf Shores.", "candidate_1": "A Tranquil Oasis of Natural Beauty.", "choice": 0}The reward model is central to the RLHF process, providing a mechanism to quantify the alignment of model outputs with human preferences. During the training phase, human feedback is used to adjust the parameters of the reward model, ensuring that it accurately reflects human judgments.
At inference time, the reward model deviates from its training protocol by evaluating single outputs to predict a scalar reward, without the need for a comparative output. This capability allows the reward model to assess the quality of any given response in isolation, facilitating its integration into the model's fine-tuning process.
Using the reward models, the language model is fine-tuned through Proximal Policy Optimization (PPO). This step involves adjusting the model's parameters to maximize the rewards predicted by the reward model, effectively aligning the model's outputs with human preferences, and is described in more detail in the next section.
Step 3: Reinforcement Learning (RL)
In Reinforcement Learning (RL), the environment refers to the context or setting within which an agent operates and makes decisions. The state is a specific condition or situation of the environment at a given time, which the agent observes before taking an action. The policy is a strategy or a set of rules that guides the agent's decisions on what actions to take in various states to maximize its rewards and achieve its goal. Together, these elements create a framework where the agent iteratively learns the best actions to reach its objectives through trial and error, guided by feedback from the environment.

RL employs algorithms to optimize the decision-making process, with the aim of maximizing the cumulative reward. Modern algorithms like Proximal Policy Optimization (PPO)7 and concepts such as policy networks play pivotal roles in this optimization.
Key elements include:
Environment: The scenario or context in which the agent operates.
Agent: The entity making decisions based on its perception of the environment.
State: The current situation or condition of the environment.
Action: A decision or move made by the agent that affects the state.
Reward: Feedback given to the agent based on the effectiveness of its action.
Policy: The strategy or decision-making guide that determines the agent's actions in different states to achieve its goals. It effectively maps states to actions, aiming to maximize the cumulative reward over time by leveraging the agent's experiences and the feedback received through rewards.
These terms form the backbone of the RL framework but take on specific interpretations within the context of RLHF, particularly when applied to training language models (LMs). This detailed explanation, which is often glossed over in standard documentation and research papers, can greatly illuminate the operational mechanisms of RLHF.
State. In RLHF the state encompasses the input or prompt given to the language model and also includes the sequence of output tokens generated up to the current point. This definition reflects the incremental nature of text generation, where each token output is contingent on the preceding sequence.
Action. The "policy" within RLHF is determined by the language model's decoder8. This component of the LLM is responsible for generating the next token (action) in the sequence, based on the current state (the prompt and any output tokens produced so far). The decoder's function as the policy maker highlights the model's predictive capacity, using the accumulated context to decide the most appropriate subsequent action (token) to take. This decision-making process is central to the model's ability to produce coherent and contextually relevant text.
Reward. A critical distinction in RLHF is that rewards are not attributed to intermediate states occurring during the generation of each token. Instead, only the end state, demarcated by a special token such as EOS (End Of Sentence), receives a reward. The allocation of rewards at this juncture emphasizes the importance of the final output's quality and alignment with human preferences, rather than the incremental steps taken to arrive there9. The mechanism of reward in RLHF is facilitated through the reward model described above.
Essentially, the reward model evaluates the quality and relevance of the generated text (action). This evaluation then influences the policy, refining the decision-making process of the LLM's decoder for future actions. Through iterative training, this feedback loop between the reward model's evaluations and the policy adjustments enables the language model to more accurately predict and select actions that lead to higher quality and more human-aligned outputs. This optimization process ensures that the language model not only generates text that is coherent and contextually relevant but also fine-tunes its responses to better meet the nuanced expectations and preferences of human users.
RLHF represents a sophisticated approach to training language models, emphasizing the alignment of model behavior with human expectations. By leveraging the principles of reinforcement learning and incorporating human feedback into the training loop, RLHF offers a pathway to develop more intuitive, responsive, and safe AI systems. Through the use of reward models and advanced algorithms like PPO, RLHF showcases the potential of combining human insights with machine learning techniques to achieve remarkable outcomes in the realm of artificial intelligence.
Provider approaches to RLHF
OpenAI
OpenAI offers access to large language models (LLMs) through two primary avenues:
ChatGPT: This is a specifically designed and fine-tuned model for engaging in conversation. While not directly available through an API, it serves as a showcase for OpenAI's capabilities in crafting human-like dialogue.
OpenAI API: This platform provides access to a variety of base LLMs, like GPT-4, for users to integrate into their applications. OpenAI offers fine-tuning techniques through their API, including supervised tuning for well-defined tasks.
OpenAI utilizes Reinforcement Learning from Human Feedback (RLHF) to fine-tune its LLMs. While the specifics of their current implementation remain undisclosed due to competitive and safety concerns10, the website “Aligning language models to follow instructions” provides an overview11.

OpenAI has also shifted its default API models to these RLHF-tuned versions, emphasizing their effectiveness12. This suggests that the RLHF process might lead to a reduction in model size (e.g., InstructGPT at 1.3B vs. GPT-3 at 175B), potentially contributing to the computational feasibility of RLHF. To be clear: This means that instead of the original model a model smaller by a factor of ~100 is used. The situation will be similar with other models, for which, however, no information is available. OpenAI doesn’t offer an API for RLHF, only Supervised Fine-Tuning13.
A key limitation lies in OpenAI's current lack of transparency. Their recent technical report on large language models acknowledges the absence of details regarding model size, training methods, or datasets used with RLHF. This approach stands in contrast to their initial vision of open research collaboration. The ongoing public dispute between co-founders Elon Musk and Sam Altman further highlights this shift.
Therefore, to gain a more comprehensive understanding of RLHF implementation, this article will explore approaches adopted by open-source models or companies with a more public development style.
Meta
Meta AI, while not offering all the details publicly, focuses on open-source accessibility and fine-tuned models for specific functionalities with their Llama2 large language models (LLMs)14. This approach contrasts with some other companies who prioritize secrecy around their LLM technology.

The paper "Llama 2: Open Foundation and Fine-Tuned Chat Models15" details the development and fine-tuning methodologies, including Reinforcement Learning from Human Feedback (RLHF), used to enhance the performance of Llama 2 models. It serves as an in-depth resource on the fine-tuning process, highlighting the significant role of RLHF in improving model alignment with human preferences. This document is particularly valuable for those seeking detailed insights into the technical aspects and outcomes of applying advanced fine-tuning techniques to language models.
Google
Google Cloud has recently introduced two notable models: Gemini and Gemma16. Gemini is a family of closed models, detailed in a paper17 highlighting its capabilities as highly capable multimodal models. Conversely, Gemma, deriving from Gemini's research and development, represents a family of open models, aimed at broadening accessibility and application in various fields18. These developments underscore Google's commitment to advancing language and multimodal model technology. However, it's worth noting that specific details regarding Reinforcement Learning from Human Feedback (RLHF) in these models are not provided in the available documentation.
Google Cloud offers a range of large language model (LLM) services through Vertex AI, their machine learning platform. Google's approach to model tuning encompasses both Supervised Tuning and Reinforcement Learning from Human Feedback (RLHF). Their comprehensive documentation19 guides users on leveraging Google Cloud services to refine text models (not including Gemini) through these methods.
The process involves preparing relevant training data, uploading it to Google Cloud Storage, setting up a tuning job on Vertex AI with the specified method and model, and deploying the tuned model to an endpoint for use. Additionally, Google facilitates learning through Vertex AI SDK for Python, offering notebooks on Colab, GitHub, and Vertex AI Workbench for hands-on experience with RLHF tuning.
A more technical introduction
For readers interested in the technical intricacies of Reinforcement Learning from Human Feedback (RLHF), Hugging Face offers a detailed exploration of RLHF's principles and applications here. While this blog post delves into how RLHF is implemented and its significance in the development of more responsive and accurate language models, those seeking a deeper understanding of RLHF's mechanics and its impact on AI should consider this resource.
Google Cloud offers RLHF for a few models: https://cloud.google.com/vertex-ai/generative-ai/docs/models/tune-text-models-rlhf
You may have noticed that ChatGPT sometimes generates two outputs and asks you for your preference. This is obviously used for SFT to improve ChatGPT.
https://platform.openai.com/docs/guides/fine-tuning
https://cloud.google.com/vertex-ai/generative-ai/docs/models/tune-models#supervised-tuning
https://platform.openai.com/docs/guides/fine-tuning/preparing-your-dataset
https://cloud.google.com/vertex-ai/generative-ai/docs/models/tune-text-models-rlhf
https://openai.com/research/openai-baselines-ppo
https://arxiv.org/pdf/1706.03762.pdf
In Reinforcement Learning (RL), the challenge of credit assignment involves determining which actions (or sequences of actions) are responsible for receiving a particular reward, especially when rewards are sparse or delayed. This stands in contrast to supervised learning, where each input comes with a corresponding correct output, making it clear which actions lead to successful outcomes. In the context of emphasizing the final output's quality and alignment with human preferences in RLHF, the credit assignment problem underscores the difficulty of attributing the overall reward to specific intermediate actions or decisions made by the model. Unlike supervised learning, where feedback is immediate and direct for each training example, RL must navigate the complexity of understanding which parts of a sequence contribute to the end result, making the process of training and fine-tuning models to align with human preferences more challenging and nuanced.
https://arxiv.org/abs/2303.08774
https://openai.com/research/instruction-following
https://openai.com/research/instruction-following
https://platform.openai.com/docs/guides/fine-tuning
https://llama.meta.com/
(https://arxiv.org/abs/2307.09288
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
https://arxiv.org/pdf/2312.11805.pdf
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
https://cloud.google.com/vertex-ai/generative-ai/docs/models/tune-models
This article comes at the perfect time. I was just pondering the engeenering challenges of RLHF. You've explained it so clearly. What if we could democratize this by drastically lowering computational costs? Imagine the innovation! Really appreciate the insights.