
How to run CUDA in a Colab notebook
Develop and test high-performance CUDA applications directly within a browser, without the need for local GPU resources.


In the realm of high-performance computing, NVIDIA's GPUs like the A100 and V100 have set new benchmarks for computational speed, especially for tasks related to machine learning, data analysis, and scientific computing. Coupled with CUDA, NVIDIA's parallel computing platform and programming model, developers can unlock dramatic performance gains by leveraging the power of these GPUs. In this article, I'll guide you through running C/C++ CUDA code in a Google Colab notebook, specifically using Nvidia A1001, V1002 or T43 GPUs4.
CUDA
Let's start with what Nvidia’s CUDA is:
CUDA is a parallel computing platform and application programming interface (API) that allows software to use certain types of graphics processing units (GPUs) for accelerated general-purpose processing, an approach called general-purpose computing on GPUs (GPGPU).
CUDA is a software layer that gives direct access to the GPU's virtual instruction set and parallel computational elements for the execution of compute kernels. In addition to drivers and runtime kernels, the CUDA platform includes compilers, libraries and developer tools to help programmers accelerate their applications5.
If you want to find out more, take a look at the CUDA C++ Programming Guide.
Please note that frameworks such as TensorFlow or PyTorch already have built-in CUDA support for training machine learning models. Therefore, you do not have to work with low-level CUDA programming in this case.
Google Colab
Google Colab is a free Jupyter notebook environment that requires no setup and runs entirely in the cloud. It allows users to write and execute Python code through the browser. Colab supports the option to choose different runtimes, including the powerful Nvidia A100, V100 or T4 GPUs, besides Google's TPUs, providing a significant boost for computational tasks. Please note that the use of GPUs is associated with costs6.

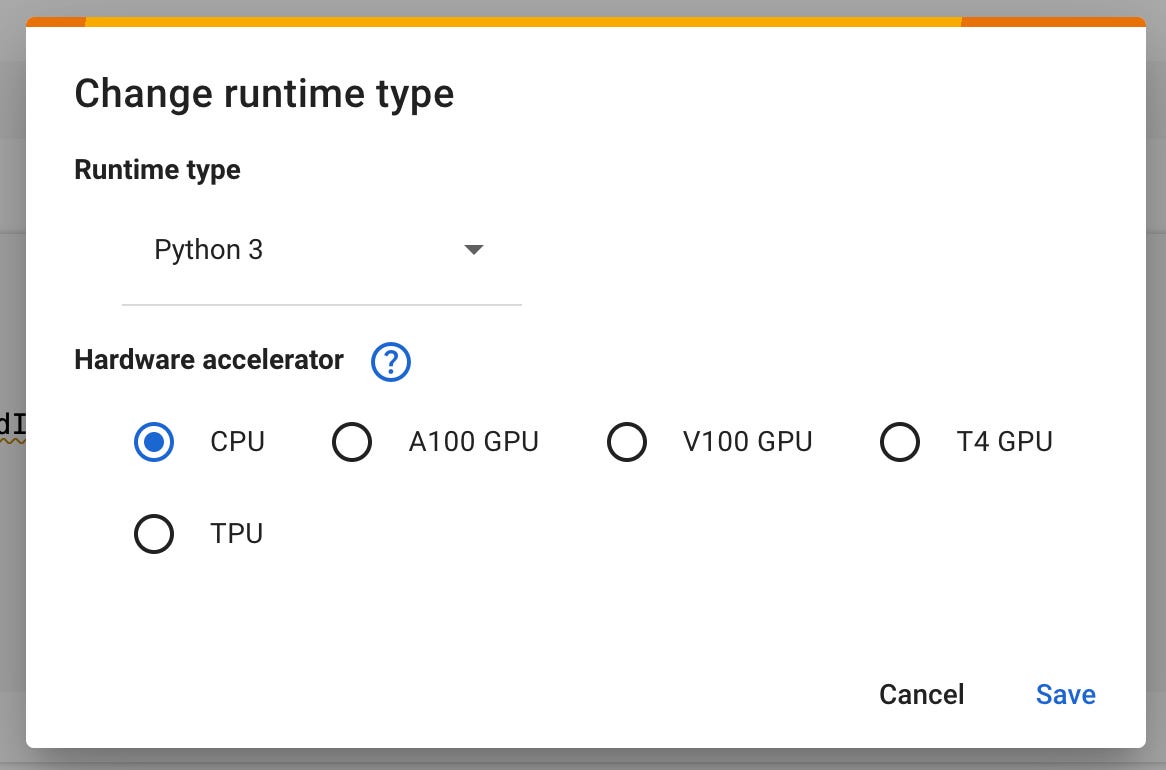
You have to select a runtime with A100, V100 or T4 GPU to run the code. In Colab, click on the chevron at the top right below the setting icon.

and select a GPU (either A100, V100 or T4 - I used the V100):
nvcc4jupyter plugin for Jupyter Notebooks
To bridge the gap between CUDA C++ and Jupyter Notebooks, the nvcc4jupyter plugin comes into play. It allows for the compilation and execution of CUDA C++ code directly within a Jupyter Notebook environment, such as Colab. For more detailed information on nvcc4jupyter, you can visit its GitHub repository.
Getting Started with "Hello World"
Let's dive into the practical aspect by starting with a simple "Hello World" program in CUDA C++. Here are the steps to set up and run your CUDA code in Colab:
1. Installing nvcc4jupyter: First, you need to install the nvcc4jupyter plugin in your Colab notebook. This can be done by running
!pip install nvcc4jupyterin a cell.
2. Loading the Extension: After installation, load the extension by running
%load_ext nvcc4jupyterin a new cell.
3. Writing CUDA Code: Now, you're ready to write your CUDA code7. Use the %%cuda magic command at the beginning of a cell to indicate that the following code is CUDA C++ code:
%%cuda
#include <stdio.h>
__global__ void hello(){
printf("Hello from block: %u, thread: %u\n", blockIdx.x, threadIdx.x);
}
int main(){
hello<<<2, 2>>>();
cudaDeviceSynchronize();
}Run the cell and you should get this output:
Hello from block: 0, thread: 0
Hello from block: 0, thread: 1
Hello from block: 1, thread: 0
Hello from block: 1, thread: 1Compiling with nvcc Arguments
The NVIDIA CUDA Compiler Driver NVCC (nvcc8) controls the compilation process. It has various command-line options to optimize and control the behavior of your CUDA code compilation. A detailed list of nvcc command options can be found here.
This line compiles the code with Nvidia’s cuRAND library for generating random numbers9:
%%cuda -c "-l curand"This allows us to run the following program10 in a new cell:
%%cuda -c "-l curand"
/*
* This program uses the host CURAND API to generate 100
* pseudorandom floats.
*/
#include <stdio.h>
#include <stdlib.h>
#include <cuda.h>
#include <curand.h>
#define CUDA_CALL(x) do { if((x)!=cudaSuccess) { \
printf("Error at %s:%d\n",__FILE__,__LINE__);\
return EXIT_FAILURE;}} while(0)
#define CURAND_CALL(x) do { if((x)!=CURAND_STATUS_SUCCESS) { \
printf("Error at %s:%d\n",__FILE__,__LINE__);\
return EXIT_FAILURE;}} while(0)
int main(int argc, char *argv[])
{
size_t n = 100;
size_t i;
curandGenerator_t gen;
float *devData, *hostData;
/* Allocate n floats on host */
hostData = (float *)calloc(n, sizeof(float));
/* Allocate n floats on device */
CUDA_CALL(cudaMalloc((void **)&devData, n*sizeof(float)));
/* Create pseudo-random number generator */
CURAND_CALL(curandCreateGenerator(&gen,
CURAND_RNG_PSEUDO_DEFAULT));
/* Set seed */
CURAND_CALL(curandSetPseudoRandomGeneratorSeed(gen,
1234ULL));
/* Generate n floats on device */
CURAND_CALL(curandGenerateUniform(gen, devData, n));
/* Copy device memory to host */
CUDA_CALL(cudaMemcpy(hostData, devData, n * sizeof(float),
cudaMemcpyDeviceToHost));
/* Show result */
for(i = 0; i < n; i++) {
printf("%1.4f ", hostData[i]);
}
printf("\n");
/* Cleanup */
CURAND_CALL(curandDestroyGenerator(gen));
CUDA_CALL(cudaFree(devData));
free(hostData);
return EXIT_SUCCESS;
}Run the cell and you should get an output similar to this:
0.1455 0.8202 0.5504 0.2948 0.9147 0.8690 0.3219 0.7829 0.0113 0.2855 0.7816 0.2338 0.6791 0.2824 0.6299 0.1212 0.4333 0.3831 0.5136 0.2987 0.4166 0.0345 0.0494 0.0467 0.6166 0.6480 0.8685 0.4012 0.0631 0.4972 0.6809 0.9350 0.0704 0.0458 0.1324 0.3785 0.6457 0.9930 0.9952 0.7677 0.3217 0.8210 0.2765 0.2691 0.4579 0.1969 0.9555 0.8739 0.7996 0.3810 0.6662 0.3153 0.9428 0.5006 0.3369 0.1490 0.8637 0.6191 0.6820 0.4573 0.9261 0.5650 0.7117 0.8252 0.8755 0.2216 0.2958 0.4046 0.3896 0.7335 0.7301 0.8154 0.0913 0.0866 0.6974 0.1811 0.5834 0.9255 0.9029 0.0413 0.9522 0.5507 0.7237 0.3976 0.7519 0.4398 0.4638 0.6094 0.7358 0.3272 0.6961 0.4893 0.9698 0.0456 0.2025 0.9491 0.1516 0.0424 0.6149 0.5638 Example Notebook
To help you get started, I've prepared a Colab notebook that demonstrates the setup and basic usage of CUDA C++ within the Colab environment, including compiling with nvcc arguments.
Conlusion
By following the steps outlined in this article and utilizing the example notebook, you should now be equipped to run C/C++ CUDA code in a Colab notebook, harnessing the power of Nvidia's A100 or V100 GPUs for your computational tasks. This opens up a realm of possibilities for developing and testing high-performance CUDA applications directly within a browser, without the need for local GPU resources.
https://www.nvidia.com/en-us/data-center/a100/
https://www.nvidia.com/en-us/data-center/v100/
https://www.nvidia.com/en-us/data-center/tesla-t4/
See here for a comparison of the performance and cost of these GPUs in Colab: https://www.domainelibre.com/comparing-the-performance-and-cost-of-a100-v100-t4-gpus-and-tpu-in-google-colab/
https://en.wikipedia.org/wiki/CUDA
https://colab.research.google.com/signup
https://github.com/andreinechaev/nvcc4jupyter
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
https://docs.nvidia.com/cuda/curand/index.html
adapted from https://stackoverflow.com/questions/56854243/how-to-link-the-libraries-when-executing-cuda-program-on-google-colab/56908350#56908350, also see here for the original example: https://docs.nvidia.com/cuda/curand/host-api-overview.html#host-api-example